

真是热闹的一周。
周一,Kimi刚发完Kimi K2.6;周五,万众瞩目的DeepSeek V4就来了。
这种感觉很熟悉。
过去一年,这两家公司不是前后脚发模型,就是前后脚发技术论文,不是你把市场热度点着了,就是我把技术讨论接过去了。
更早之前,说起中国开源模型,几乎条件反射地想到DeepSeek。
尤其是DeepSeek发布R1之后,这家公司不仅凭一己之力改写了全球市场对中国AI的印象,而且唤醒了其他中国的AI创业团队的“信心”。
于是,我们看到,更多的中国AI创业团队开始做出非常竞争力的模型,带来非常有影响力的技术研究成果。
2025年7月,被《自然》杂志称为“又一个DeepSeek时刻”的Kimi K2模型,在底层架构上首次大规模验证了二阶优化器 Muon,同时采用了 DeepSeek验证过的 MLA注意力机制。
到了2026年4月,DeepSeek V4在架构上也跟进 Kimi K2采用 Muon优化器,取代过去已经使用了10年的Adam优化器。
这可能是开源最大的价值:让中国公司共享技术,加速追赶美国的闭源巨头。
它们是中国目前唯二,总参数超过万亿、已权重公开的中国模型。也是最有国际影响力的中国AI模型代表。全球市值最高的英伟达公司在展示下一代芯片性能时,用的模型正是来自 DeepSeek 和Kimi。
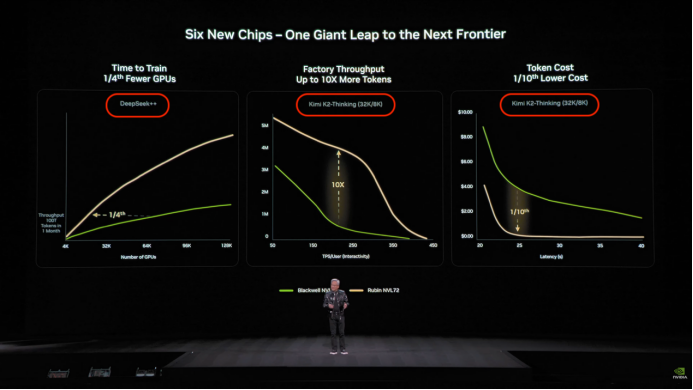
不仅如此,他们也都在挑战深度学习网络的底层架构,DeepSeek有mHC残差连接,Kimi有引发硅谷核心技术圈讨论的“注意力残差”。

虽然说DeepSeek V4和Kimi K2.6在同一周发布,但其实两个模型各有技术侧重点。
V4的核心突破在于百万上下文的成本重构,它通过全新的混合注意力机制,将单token推理的计算量压缩到V3.2的27%,KV Cache降至10%。
这套方案结合了压缩稀疏注意力和重度压缩注意力,让百万级上下文从技术演示变成了可以普及的基础设施。
V4同时针对agent场景做了专项优化,后训练阶段把agent作为独立方向单独训练,工具调用格式从JSON换成带特殊token的XML结构,跨轮次推理痕迹在工具调用场景下完整保留。
DeepSeek还自建了名为DSec的沙箱平台,单集群可并发管理数十万个沙箱实例,用来支撑agent强化学习训练和评测。
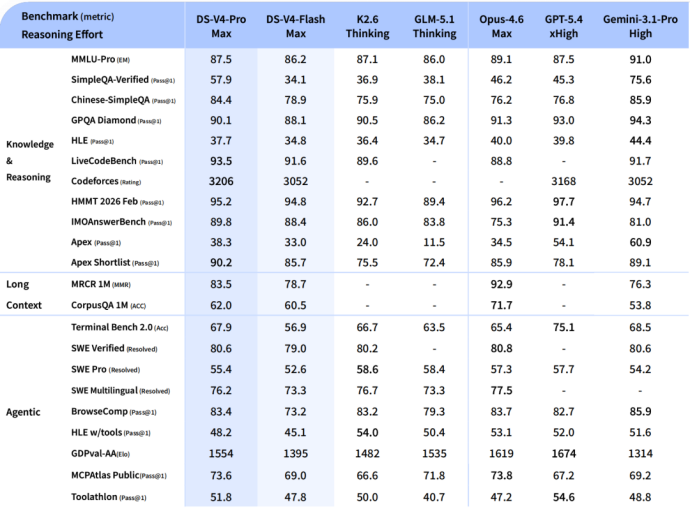
K2.6的方向则更偏向长程编码和agent集群。它在Kimi Code Bench内部评测中得分68.2,比K2.5的57.4提升约20%。
最高可支持300个子agent并行完成4000个协作步骤。

2025年2月,Kimi 发布 Moonlight系列模型,首次将二阶优化器Muon应用于480亿参数的大模型,验证了新一代优化器的效果。
2025年4月,Kimi-VL模型发布,在Moonlight模型的技术上,引入MoonViT视觉编码器,为之后的多模态理解模型打下基础。
2025年7月,Kimi首次将Muon优化器扩展到万亿参数的规模,推出 K2 开源模型。
2025年10月,Kimi发布Kimi Linear,这是Kimi提出的一种线性注意力架构,核心目标是在保住长上下文能力的同时,把大模型处理超长文本的计算和显存成本降下来。
这说明杨植麟已经不满足于只做模型了,他想对模型的底层架构动手。
随后,Kimi发布并开源支持图片和视频理解的万亿参数模型Kimi K2.5。
2026年3月,Kimi发布注意力残差的论文,继续对Transformer的底层结构下手。
这篇论文在X上收获了马斯克本人的称赞。
在然后就到了前几天的K2.6,这是一个围绕长周期编码、agent执行、工程任务能力的模型。
从产品定位的演变可以看出,Kimi正在从消费级对话产品往生产力工具转型。
2026年3月,杨植麟在英伟达GTC大会上发表演讲,系统介绍Kimi技术路线,他用三个关键词概括Kimi的Scaling策略:Token效率、长上下文、agent集群。
他表示,要推动大模型智能上限的持续突破,必须对优化器、注意力机制及残差连接等底层基石进行重构。
当前的Scaling已经不再是单纯的资源堆砌,而是要在计算效率、长程记忆和自动化协作上同时寻找规模效应。
一家公司最怕的是,只有媒体在讨论你,开发者却不用你。
但Kimi不一样,无论是在OpenRouter上还是绝大多数agent工具的默认接口里, K2.5和K2.6都是主流选项。
截止发稿,Kimi和DeepSeek都出现在OpenRouter的TOP3模型里,在AA的榜单上,K2.6甚至暂时占得先机。
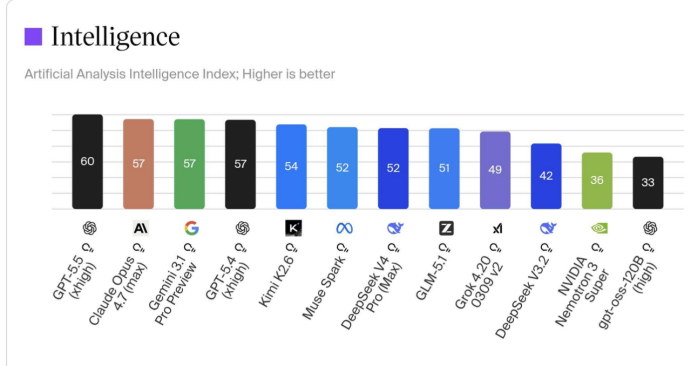
而在K2.6这里,模型继续强化agent、长任务、编码能力,也是同一个信号。杨植麟真正押注的,就是生产力场景。
这也是Kimi这一年最关键的变化。
它不再只是告诉用户“我能帮你读更长的文件”,而是在回答更底层的问题,模型怎样才能在更长时间、更复杂任务、更高工具调用密度下保持稳定?
长上下文解决的是记忆和信息承载;线性注意力解决的是成本和扩展性;agent集群解决的是复杂任务拆解;编程能力解决的是模型的理解和执行。
它们看起来是几条不同产品线,其实背后指向同一个方向,Kimi想把Kimi从一个好用的聊天窗口,变成可以承接真实工作的基础模型。
4月,杨植麟受邀参加总理主持的经济形势专家和企业家座谈会,作为唯一的大模型创业者代表发言。这个1993年出生的年轻人,成为座谈会上最年轻的参会者。
一个月前,他刚在2026中关村论坛年会全体会议上发表演讲,系统阐述了中国AI团队如何通过底层架构的“推倒重建”,打破沿用十年的行业技术标准。
显然,Kimi已经从一家创业公司,变成了代表中国AI技术路线的符号之一。
Kimi这一年的成长路径,和DeepSeek的路径有明显差异。两家公司的技术选择不同,但也正因如此,才让中国开源模型有了更多可能性。

过去我们写这两家公司,容易写成“谁的模型好”、“谁才是下一个OpenAI”。
但这其实是个误区。
DeepSeek和Kimi,不该被简单理解成“谁赢谁输”。它们更像中国开源模型对外竞争的两条腿。不存在谁取代谁,而是应该互相刺激互相促进。
DeepSeek和Kimi相继证明了一件事,做前沿模型不一定需要无限的资源,关键在于算法创新和工程优化。它们在模型算法、工程效率、开源路线和降低推理成本上的贡献,仍然是中国AI过去一年最重要的技术事件之一。
它们彼此竞争,但也彼此抬高了中国开源模型的上限。
真正重要的不是它们谁先到终点,而是它们把中国模型的竞争维度拆开了。
过去我们评价一家模型公司,很容易只看榜单、参数、价格、发布会声量。
但模型公司真正的护城河,已经不再是“模型聪不聪明”、“模型性能如何”这些事了。现在围绕模型的叙事,是它能不能形成一整套技术路线。
DeepSeek把第一件事做得很彻底。它让外界看到,中国公司可以用更高的工程效率,把模型训练和推理成本打下来,可以把技术报告写到足够透明,可以把权重开放到足够激进。
它建立的是一种开源信任。开发者愿意研究它、复现它、部署它,是因为它不只是给了一个API,而是把模型背后的方法论也拿了出来。
Kimi补上的是另一块。
Kimi最早被用户记住,是因为长文本和聊天产品,但K2.6之后,它讲的已经不是一个更会聊天的助手,而是模型如何进入真实工作流。
长程编码、Agent集群、工具调用、长周期任务,这些能力没有“霸榜”那么直观,但它们决定模型能不能从“被试用”走向“被依赖”。
如果说DeepSeek解决的是模型够不够强、够不够便宜、够不够开放的问题,Kimi更关心的是模型能不能真的替人完成复杂任务。
所以这两家公司放在一起看,意义反而更大。
作为观察者和用户,我们肯定希望都存在,这样产业才能发展。
中国AI真正值得兴奋的,不是终于出了一个DeepSeek。
而是在DeepSeek的带动下,Kimi们依然能靠自己成长为一座座大山。
这说明中国AI公司已经开始在不同维度上找到自己的位置,不再是简单模仿,是真正的在探索自己独有的那条技术路线。
DeepSeek和Kimi的技术互相赋能,也说明了一件事,开源生态的价值在于协作。
现在的问题不是DeepSeek和Kimi谁更强,而是它们能不能继续保持这种竞争关系,继续在技术上互相刺激。
中国开源模型要真正在全球站稳脚跟,需要的不是一家独大,而是多家公司在不同方向上都做到世界级水平。DeepSeek和Kimi的存在,让这个可能性变得更大。