

编译 | 高远瞩
编辑 | 漠影
智东西4月17日报道,一个成立仅两年的机器人初创公司Physical Intelligence,刚刚拿出了让整个湾区AI圈为之震动的新成果。其最新发布的机器人基础模型π0.7,能够让机器人执行从未被明确训练过的任务:从使用空气炸锅烹饪红薯,到在一台从未见过任何衣物折叠数据的工业机器人上成功叠好T恤。
更令人惊讶的是,这些能力并非刻意设计,而是在训练过程中“涌现”出来的。
“我的经验一直是,当我深入了解数据中的内容时,我基本上可以猜出模型能做什么。我很少感到惊讶。但过去几个月是我第一次真正感到惊讶。”Physical Intelligence研究科学家Ashwin Balakrishna在论文发布后坦言。
他随机买了一个齿轮组,问机器人“你能转动这个齿轮吗?”结果机器人真的做到了。这种超越死记硬背、能够组合技能解决新问题的能力,在机器人领域尚属首次。
π0.7的出现,可能预示着机器人AI正接近类似大语言模型领域的“GPT-2时刻”,其能力开始以超出基础数据预期的方式增长。
一、零基础上手空气炸锅:只见过两个相关片段,却能学会使用
论文中最具冲击力的发现,来自于π0.7对空气炸锅的使用。
当研究者要求它“用空气炸锅烹饪一个红薯”时,它完成了部分任务,比如打开炸篮、尝试放入红薯,但未能完全成功。这已经足够令人惊讶,因为模型从未见过完整的“拿起红薯-打开炸篮-放入-关闭-启动”这一链条。
更令人振奋的是,当研究者采用“语言指导”的方式,像向新员工解释事情一样,逐步给出指令:“打开空气炸锅”“拿起红薯”“把红薯放进炸篮”“关闭空气炸锅”……π0.7能够精准地跟随这些实时指令,成功完成整个任务。
Physical Intelligence研究员、斯坦福大学计算机科学博士生Lucy Shi透露,早期的一个空气炸锅实验成功率只有5%,但在花了大约半小时优化提示工程(prompt engineering)后,成功率跃升至95%。“有时失败模式不在机器人或模型上,”她说,“而在于我们不擅长提示工程。”
这一现象让人不禁联想到大语言模型的“涌现”能力:就像GPT-2能写出关于“安第斯山脉独角兽”的奇怪故事一样,π0.7也能将从未一起出现过的技能重新组合。
Physical Intelligence联合创始人、UC Berkeley教授Sergey Levine评价道:“它到底从哪里学会空气炸锅是什么?这很难追溯。但看到机器人领域出现这种情况,真的很特别。”

人类用逐步指令“教”机器人使用空气炸锅的过程
二、跨具身迁移:让笨重的工业臂学会叠衣服,性能媲美人类专家
如果说空气炸锅案例展示了π0.7能组合不同技能,解决从未见过的任务,那么跨具身迁移(cross-embodiment transfer)实验则展示了它在物理形态层面的迁移能力。
研究者决定在一个完全不同的机器人上测试π0.7:双臂UR5e系统。这是两台UR5e工业级机械臂,带有Robotiq平行夹爪。它们的手臂更长、更重,惯性大,夹爪也不够精确,远程操作本身就很困难。关键是,研究者从未用这个平台收集过任何衣物折叠的数据。也就是说,对于UR5e来说,折叠T恤是一个“零样本”(zero-shot)任务。
结果令所有人震惊:π0.7不仅成功地在UR5e上折叠了T恤和毛巾,而且其任务进度达到了85.6%,成功率达到了80%。
为了给这个数字提供参照,研究团队进行了一项人类受试者研究:招募了10名平均拥有375小时远程操作经验的顶级操作员(均处于公司操作员经验排名的前2%),让他们在UR5e上“零样本”尝试折叠T恤。这些操作员虽然熟悉源机器人,但从未在UR5e上做过这个任务。结果显示,人类操作员的平均任务进度为90.9%,成功率为80.6%。π0.7的表现几乎与这些专家持平。
并且,π0.7在UR5e上采用的折叠策略与源机器人完全不同。在源机器人上,人类操作员通常以倾斜的末端执行器接近布料,先压住织物再提起;而在UR5e上,π0.7自发地采用垂直抓取,这是更适合长臂、高惯性机器人的策略。
模型没有盲目模仿训练数据中的动作,而是根据目标具身的物理特性调整了自己的行为。这正是跨具身迁移的本质:不是复制运动轨迹,而是理解任务目标并找到适合当前身体的新解法。
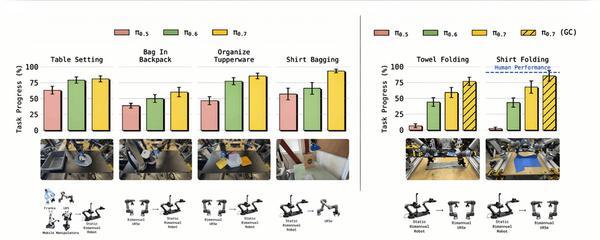
跨具身迁移结果:左侧对比π0.5、π0.6、π0.7在多个跨具身任务上的成功率,右侧展示UR5e折叠衣物的任务进度和人类对比

展示策略自适应变化(倾斜抓取 vs 垂直抓取)
三、开箱即用:从削蔬菜皮到组装盒子,全面对标专用模型
除了空气炸锅和跨具身折叠,π0.7在常规的灵巧操作任务上也交出了一份亮眼的成绩单。
Physical Intelligence将π0.7与之前通过强化学习微调的专用模型π0.6*进行了系统比较。任务包括:制作浓缩咖啡(多步骤:磨粉、压粉、扣入手柄、萃取)、组装盒子(将平板纸盒折叠成立体盒子)、折叠T恤和短裤、削蔬菜皮(西葫芦、黄瓜、胡萝卜)、更换垃圾袋、切西葫芦、做花生酱三明治等。
结果显示,π0.7在所有任务上都达到了与专用模型相当甚至更高的性能。
例如,在衣物折叠任务中,π0.7的吞吐量(每小时成功次数)甚至超过了RL专家模型。在需要记忆的任务中,π0.7也不需要任何微调,开箱即用就达到了与专用记忆模型(π0.6-MEM)相似的水平,比如“找到藏在抽屉里的物体”或“交换三个杯子的位置”。
在指令遵循方面,π0.7同样大幅超越了前代模型π0.5和π0.6。
研究者在4个未见厨房和2个未见卧室中设计了14个指令遵循场景,每个场景需要机器人执行3-6步开放式指令,π0.7的整体指令遵循成功率显著高于前代。
更令人印象深刻的是,π0.7能够处理“分布外”的复杂指代指令,例如“拿起我会用来喝汤的物体”或“拿起最大盘子上的水果”。当结合子目标图像(GC模式)时,性能进一步提升。
此外,π0.7还能打破数据集的偏见:在“反向清理”任务中,数据中通常是“垃圾扔垃圾桶、盘子放餐盘回收箱”,但π0.7能够遵循指令将垃圾放入餐盘回收箱、盘子放入垃圾桶。在“反向冰箱到微波炉”任务中,数据只有“冰箱→微波炉”,π0.7却能从微波炉取出食物放回冰箱,这极大依赖子目标图像提供的视觉引导。
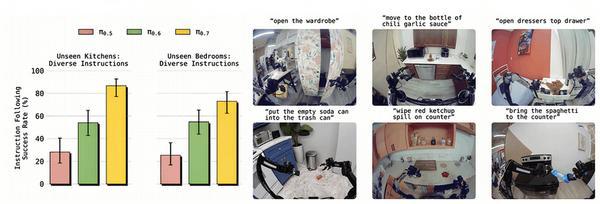
指令遵循成功率
四、π0.7的技术核心:5B参数、异构数据与跨任务泛化
π0.7模型架构概览:
π0.7是一个参数量约50亿(5B)的视觉-语言-动作模型(VLA),其核心组件包括:
1、视觉-语言骨干网络:基于Gemma3 4B模型(含4亿参数的视觉编码器),负责处理多视角图像、语言指令和机器人本体感知信息。
2、动作专家模块:一个8.6亿参数的Transformer,采用流匹配(Flow Matching)目标生成连续动作,输出长度为50步的动作块(action chunk)。
3、记忆机制:沿用MEM(多尺度具身记忆,Multi-scale Embodied Memory)架构,对历史观测进行时空压缩,使模型能处理变长的历史帧。
4、多模态上下文:训练时模型接受四种额外提示——子任务语言指令、子目标图像(subgoal image)、片段元数据(episode metadata)和控制模式(关节空间或末端执行器控制)。训练时每种提示会随机丢弃一部分,使模型在推理时能灵活组合使用。
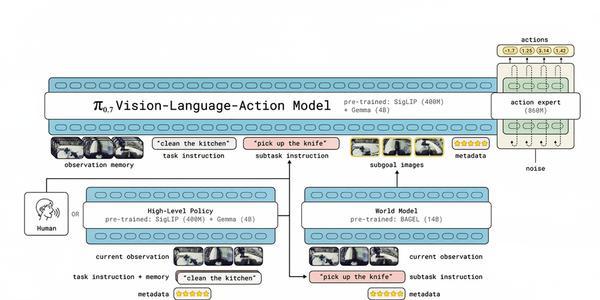
π0.7模型架构图
π0.7训练数据特点:
π0.7使用了大规模异构数据,包括多种机器人平台的演示数据、自主策略评估产生的成功与失败数据、人类远程操作干预数据、第一人称人类视频,以及互联网上的非机器人数据(如图像问答、视频字幕等)。
训练时,模型还接受四种额外提示作为数据上下文:子任务语言指令、子目标图像(subgoal image)、片段元数据(episode metadata)和控制模式(关节空间或末端执行器控制)。每种提示在训练中会随机丢弃一部分,使模型在推理时能灵活组合使用。
模型通过元数据标注区分不同质量的数据,从而能从次优数据中学习而不损害性能。这些元数据包括:整体速度(以500步为一档,如1750-2250步标为“2000步”)、整体质量(1-5分)、错误标签(是否犯错)和控制模式。
训练中团队还采用了“知识绝缘”技术(KI),让语言骨干网络的梯度与动作模块隔离,避免动作预测干扰预训练的视觉语言特征,从而更稳定地学习多模态上下文。
通过这种设计,π0.7学会了根据提示中的“质量=5”“错误=false”“速度=8000”等条件,输出高质量、快速、无错误的动作。而训练数据中的次优片段则提供了丰富的“负面样本”和状态多样性,增强了模型的鲁棒性(Robustness)。
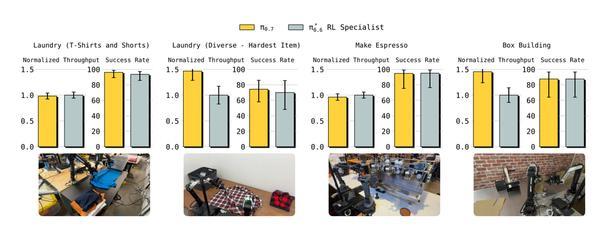
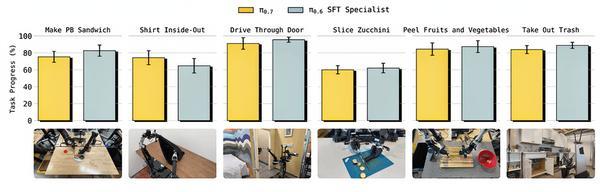
开箱即用性能对比: 展示π0.7与π0.6*专家模型在浓缩咖啡、盒子搭建、衣物折叠等任务上的成功率和吞吐量对比
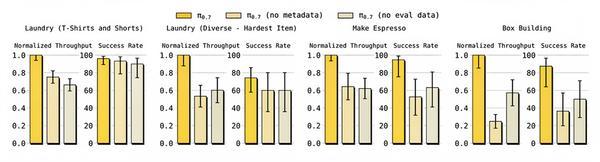
元数据消融实验结果
五、能力突破拐点已至,三大局限仍待突破
尽管π0.7取得了令人瞩目的成果,但研究团队并没有回避其局限性。
首先,π0.7目前还无法仅凭一个高层次的指令自主执行复杂的多步骤任务。
“你不能告诉它,‘嘿,去给我烤些面包片’,”Sergey Levine坦言。“但如果你逐步引导它——‘对于烤面包机,打开这个部分,按下那个按钮,这样做’——那么它实际上往往能做得很好。”也就是说,对于长时程、多阶段的新任务,仍然需要人类通过语言进行“指导”或训练一个高层策略来分解子任务。
其次,机器人领域缺乏标准化的基准测试,这使得外部验证变得困难。
Physical Intelligence主要依靠与自家前代模型的对比,以及内部设计的一系列评分规则(如削蔬菜皮的完成百分比、折叠衣物的质量评分)。不同实验室之间的任务和环境差异很大,难以直接比较。
第三,也是根本性的问题:语言模型有整个互联网可以学习,而机器人没有。
尽管π0.7也使用了网络预训练、人类视频等数据,但物理世界的交互数据仍然稀缺且昂贵。研究者承认,对于某些任务,零样本泛化的成功率(60-80%)仍然低于分布内任务(超过90%)。未来需要更高效的数据利用方法,例如利用π0.7本身的可引导性进行自主强化学习。
此外,由于训练数据集规模巨大且内容庞杂,研究者往往难以确切知道某个能力究竟来自哪个具体片段。例如,空气炸锅的知识可能来自那两个片段,也可能来自网络上无数张厨房图片的预训练。这种“黑箱”特性与大型语言模型如出一辙,但也意味着真正的组合泛化(compositional generalization)正在发生:模型不是在检索记忆,而是在重新混合。
Levine回忆起当年GPT-2生成“安第斯山脉独角兽”故事时的震撼:“它到底从哪里学到秘鲁的独角兽?那是非常奇怪的组合。现在在机器人领域看到这种情况,真的很特别。”
批评者可能会指出,机器人演示的任务看起来不如“后空翻”那样酷炫。但Levine反驳说,泛化本身看起来总是不如精心编排的特技表演那么戏剧化——但它要有用得多。
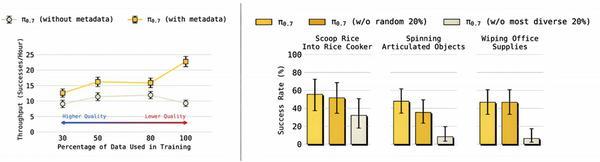
数据扩展性曲线:左图显示有元数据时,即使在数据质量下降的情况下,π0.7的性能仍能随数据量增加而持续提升;右图显示高任务多样性数据对泛化性能的关键贡献
结语:组合泛化实现突破,通用机器人“大脑”将至
π0.7的发布,标志着机器人基础模型从“死记硬背”走向“组合泛化”的初步突破。它能够在零样本下完成空气炸锅烹饪、跨具身折叠衣物等从未见过的任务,性能媲美人类专家和RL微调专用模型。这背后是多样化上下文提示、元数据条件化(conditioning on metadata)和超大规模异构数据训练的共同作用。
如今,物理智能的“GPT时刻”似乎也在悄然临近。Physical Intelligence已融资超10亿美元,最新估值达56亿美元,并正洽谈新一轮可能将其推至110亿美元的融资。
当然,也有人对此持保留态度,认为π0.7的跨具身能力目前仅限于夹爪操作,尚未涉及更复杂的全身控制,但这类质疑并未掩盖多数人对该方向的乐观预期。
尽管其仍有诸多限制:无法自主完成长链条任务、缺乏标准化评测、数据依赖性依然存在……但他们的研究成果已经向世界证明:一个可引导、可教会、可迁移的通用机器人“大脑”,不再是科幻。