

编辑:桃子
【新智元导读】老黄深夜祭出最强挑衅:所有自研芯片都是「纸老虎」!他直言谷歌TPU、亚马逊Trainium根本不敢上台打擂,并首次揭秘了英伟达从「电子到Token」的终极护城河。
自研芯片全是「纸老虎」!
在最新访谈中,英伟达CEO甩出了一句极其挑衅的宣言——
谷歌TPU没来,亚马逊Trainium没来,根本没一个敢露面。

直白讲,在AI算力的终极对决赛中,除了英伟达,能打的对手还没出现!
在近两小时播客中,老黄与主持人Dwarkesh Patel展开了一场极具火药味且深度的对话。
他不仅重申了英伟达的技术护城河,更对当前的全球竞争格局,表达了冷峻的预判。
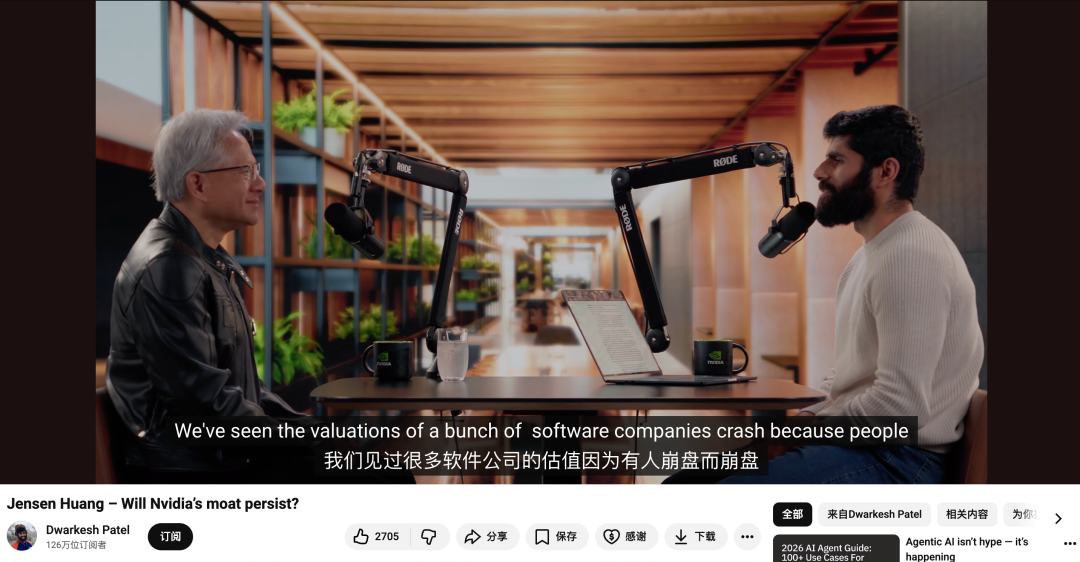
访谈中,最震撼人的一个镜头是——
面对别人的质疑,老黄霸气外露地回怼道,「我醒来从没觉得自己是个loser」。
「我们又不是一辆汽车(We are not a car)」。
|
|
|
自动播放
近两小时对谈中,所有的精彩亮点如下:
公开叫阵TPU、Trainium上MLPerf打擂,至今无人应战;
抛出新思维模型:输入电子、输出token,中间层就是英伟达;
英伟达拥有全球最低的TCO,在同等能耗下,token产出效率世界第一;
罕见认错,低估了Anthropic这步棋。但Anthropic只是特例,全世界只有一个;
真正卡脖子的不是EUV光刻机,是水管工和电工。

把「电子」转化成token
这就是护城河
访谈一开场,Dwarkesh瞄准了英伟达护城河,提出了一个尖锐的问题——
既然英伟达本质上是设计软件,然后交给台积电代工、由海力士提供内存,那么如果未来AI让软件变得像大宗商品一样廉价,英伟达的估值是否也会崩塌?
对此,老黄提出了一个全新的「思维模型」。
输入的是电子,输出的是token,而中间层就是英伟达

他认为,制造一个token就像制造一个分子,如何让这一个token比另一个token更有价值,背后蕴含着极其高深的艺术、工程与科学。
而这种「电子到token」的转化过程极其复杂,很难被平庸化。
最重要的是,英伟达的护城河在于「五层蛋糕」生态系统,他们坚持做尽可能少、但在必须做的领域做到极难的策略。

而对于「英伟达靠锁定稀缺供应链建立护城河」的说法,老黄承认,这确实是对手难以企及的优势。
他特别强调,这种优势源于一种「前瞻性的结盟」,具体怎么讲?
合作之前,AI蓝图早就绘好了
英伟达不仅仅是砸钱买产能,更是在几年前就开始说服台积电、美光等公司的CEO,向他们描绘AI产业未来的规模。
GTC,就是一场大型「教育会」
老黄调侃道,自己的GTC演讲更像是「教育」,他必须让整个供应链看清未来的趋势,才能引导全球的资源向AI产业倾斜。


所谓的「瓶颈」,都是暂时的
当谈到逻辑芯片、CoWoS封装、HBM内存的紧缺,是否会限制AI的增速时,老黄表现得非常淡定。
他指出,在巨大的市场需求信号面前,任何硬件瓶颈通常只需2-3年就能通过大规模扩产解决。

英伟达已在「预取」(Prefetching)未来的瓶颈,技术授权是一部分,另一种方式就是「投钱」。
比如,帮助合作伙伴Lumentum、台积电提前布局硅光子、双面探测等前沿技术。
有趣的是,老黄认为真正的长久挑战往往在更下游:
- 能源: 无论是重工业化还是建设 AI 工厂,能源政策的滞后才是长期难题;
- 劳动力: 真正的稀缺资源不是EUV光刻机,而是能落地AI数据中心的「水管工和电工」。

这里再mark一下Hinton那句话,去做水管工
喊话谷歌TPU来战,没人打赢英伟达
接下来,才是整场访谈中最刺激的一部分。
Dwarkesh提出了一个令市场不安的观察:
目前全球最顶尖的三个AI模型中,其中两个(Claude和Gemini)是在谷歌TPU上训练的。
这是否意味着,英伟达GPU并非不可替代?
老黄对此进行了强有力的反击,他认为完全是「降维打击」,并把英伟达的成功归结为一种完全不同的计算范式。
自动播放
「加速计算」降维打击
TPU只是一个「张量处理单元」,英文带做的是「加速计算」。
「加速计算」的应用范围远超AI,涵盖了分子动力学、量子色动力学、流体力学、粒子物理以及大规模数据处理。
如今,AI算法演进极快。

如果明天出现一种新架构,高度可编程的CUDA可以无缝支持,而固化的ASIC芯片可能直接变成「电子垃圾」。
虽然矩阵乘法是AI的核心,但创新的关键在于——快速发明新内核。
老黄透露,Blackwell之所以比Hopper飙升50倍性能,靠的是通过CUDA对MoE等新架构,进行的深度底层协同设计。
他将CUDA比作英伟达最宝贵的资产——
全球有数亿颗英伟达 GPU,分布在所有主流云平台和边缘设备中。
开发者写出的代码,可以「一次编写,到处运行」。
他将CPU比作凯迪拉克,人人都能开得不错;而英伟达的加速器则是F1赛车。
|
|
|


虽然普通人能开到100码,但只有英伟达的专家能将其性能推向极限,帮助客户通过优化软件栈直接获得2-3倍的性能提升。
TCO经济学,token产出最多
面对「大客户是否会为了省钱而自研芯片」的质疑,老黄给出了一组非常硬核的商业逻辑:
英伟达的计算栈是全球「总拥有成本」(TCO)最低的,没有之一。

在同样的1GW数据中心里,使用英伟达架构产出的token数量,是全球最高的。
现场,老黄直接公开叫阵,欢迎Trainium、或TPU参加像InferenceMAX或MLPerf这样的第三方基准测试。
但实际上,没有人愿意「露面」。

很多人抱怨英伟达 70% 的利润率太高,但老黄一针见血地指出,即便是找博通代工 ASIC 芯片,对方也要赚走65%的利润。
为了省那5%的利润,而放弃整个生态系统的兼容性,这在商业逻辑上是讲不通的。
Anthropic只是一个特例,并非趋势
Dwarkesh追问,既然英伟达这么好,为什么Anthropic还是选择了与谷歌、亚马逊签下数十亿美元的TPU订单?

面对如此尖锐的问题,老黄又是如何自圆其说?
他用一句话总结:Anthropic只是一个特例,并非趋势。

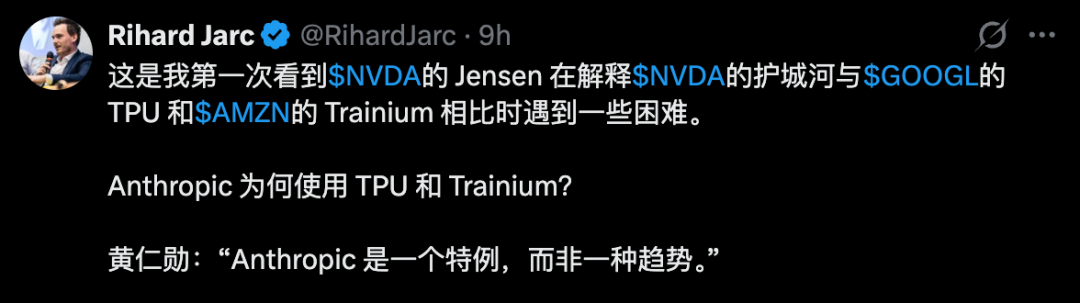
紧接着,他表示,如果没有Anthropic,TPU、Trainium的增长无从谈起,100%是Anthropic带来的。
但世界上只有一家Anthropic!

与此同时,老黄罕见地承认了策略上的失误:
当时,谷歌和亚马逊通过巨额融资,换取了Anthropic使用其自研算力的承诺。
我当时的错误在于,没有深刻意识到,如果不给这些实验室提供资金支持,他们别无选择。
英伟达的商业「哲学」:不越界
访谈的后半段,Dwarkesh又提出了一个极具诱惑力的假设——
既然英伟达拥有无可匹敌的算力资源,为什么不直接下场成为一家超大规模云服务商(Hyperscaler)?
老黄的回答揭示了英伟达的商业哲学:「做尽可能多,同时也做尽可能少」。

世界上已经有很多云服务商了。
如果英伟达自己下场做云,就是与自己的客户(亚马逊、微软等)直接竞争。
英伟达宁愿选择投资像CoreWeave这样的「原生AI云」,通过背书和资金支持,让生态系统更加多元化,而不是亲自去盖机房、拉电线。
老黄认为,一个健康的公司应当专注于那些「如果我不做,就没人能做成」的事情。
如果英伟达不去研发NVLink、不投入20年时间在亏损中坚持CUDA、不开发像cuLitho这种计算光刻库,这些技术可能永远不会出现。

投资,但不「选妃」
近来,英伟达对OpenAI、Anthropic进行了规模惊人的投资,分别达300亿和100亿美金规模。
对此,老黄非常严肃地表示,「我们不选赢家」。
一方面,这不是我们的工作,另一方面,我深知创业的不确定性。
|
|
|


他回忆起英伟达初创时,全球有60家图形芯片公司,而英伟达当时甚至是架构最「离谱」的一个。
英伟达的策略是——
如果世界需要这些伟大的AI公司存在,而VC无法提供百亿级别的资金支撑,那么英伟达就会出手。
但目的是为了让整个生态「繁荣」,而不是为了控制它们。

做好一件事,CUDA就够了
在访谈的尾声,Dwarkesh 提出了一个具有思辨性的问题:
英伟达现在财大气粗,人才济济,为什么不并行开发几种完全不同的架构?
比如像Cerebras那样的晶圆级芯片,或者像特斯拉Dojo那样的「巨型封装」,以防万一AI架构发生突变。
老黄的回答,展现了他作为顶级架构师的极度自信与理性。
模拟器已否定了一切
他直言,英伟达拥有世界顶尖的「模拟系统」。
我们可以在模拟器里,模拟出你能想象到的任何架构。结果证明,那些方案在性能和效率上都更糟。
也就是说,从数据上的验证已经否定了这一切。

Dwarkesh又问道,如果台积电先进制程(如N2/N3)产能见顶,英伟达是否会回到老旧的N7工艺重新设计 Hopper?
对此,老黄表示,这种「回流」研发的成本高得离谱。
英伟达宁愿选择在先进制程上「倾力向前」,通过先进封装和数值计算的改进来弥补产能压力。
扩产Groq:抢占「溢价token」市场
众所周知,英伟达几个月前将「推理芯片之王」Groq纳入了CUDA生态。
这背后,蕴含着老黄对推理市场「分层化」的深刻洞察:
以前token要么免费,要么极便宜。
但现在,如果更快的响应速度,能让一名年薪几十万美金的软件工程师效率翻倍,那么企业愿意支付极高的溢价。

过去英伟达追求的是高吞吐量(单位时间内产出的token总量),但现在他们开始布局「低延迟、高溢价」的推理细分市场。
这意味着未来英伟达的工厂将同时产出「平价高产」和「尊享速达」两种token。
如果没有AI革命,英伟达会怎样?
访谈以一个浪漫的假设结束。如果深度学习革命从未发生,英伟达现在会在做什么?
老黄语气中带着一种使命感:「即便没有AI,英伟达也会非常庞大」。

通用计算的终结
他的基本信念是,「摩尔定律」下的通用计算(CPU)已经走到了尽头。
无论有没有AI,科学、工程、物理、图像处理这些领域,都急需「加速计算」。
科学的民主化
英伟达的初心是让每一位学生、每一位科学家,通过一张GeForce显卡就能处理分子动力学或地震数据。
这种「加速计算」的底色,其实早在AI爆发前就已经涂就。
不仅仅是张量
老黄强调,在GTC演讲的开篇,他总会花大量时间讲计算光刻(cuLitho)、量子化学和数据处理。
AI确实令人兴奋,但这个世界上还有很多重要工作与AI无关,张量并不是计算的唯一方式。我们想帮助每一个人。
